OK, 这是 Model Compression系列的第二篇文章< FitNets: Hints for Thin Deep Nets >。在发表的时间顺序上也是在< Distilling the Knowledge in a Neural Network >之后的。FitNet事实上也是使用了KD的做法。
这片paper在introduction就很好地总结了一下前几个Model Compression paper的工作,这里稍做总结:
- < Do Deep Nets Really Need to be Deep? >主体为了突出“一个模型的复杂,不一定代表他的表达也是复杂的”。主要是用浅层的网络mimic了一个深层的网络(然而这两个网络的size是相同的)然后达到了相似的performance。其中的loss是两个网络最后的logits之间的距离。顺便值得一说的是,这篇paper中提到,需要用尽可能多的unlabeled data(不是从training set中的)来mimic,才会使student model能尽可能接近teacher model。后面这几篇应该也用了类似的方法。
- < Distilling the Knowledge in a Neural Network >主要在于改变了loss,不单单是使用logits,这点就不赘述了,上一片笔记Distilling the Knowledge in a Neural Network笔记中有详细解释。
Intuition
然后开始提到自己这个work的motivation:deep是DNN主要的功效来源,而前几个work都没有在这方面有所发展,于是这篇paper的主题就是如何去mimic一个更深但是比较小的网络,所期望的自然是他这个更深的网络能有更佳的performance。
所使用的方法直觉上来讲也是直接的:既然网络很深直接训练会困难,那就通过在中间层加入loss的方法,如此分成两块来训练,应该能得到更好的结果。至于中间的loss怎么来?自然就是通过teacher network的中间feature map来得到的。paper中把这个方法叫做Hint-based Training (HT)
Methodology
这一节详细描述一下Hint-based Training
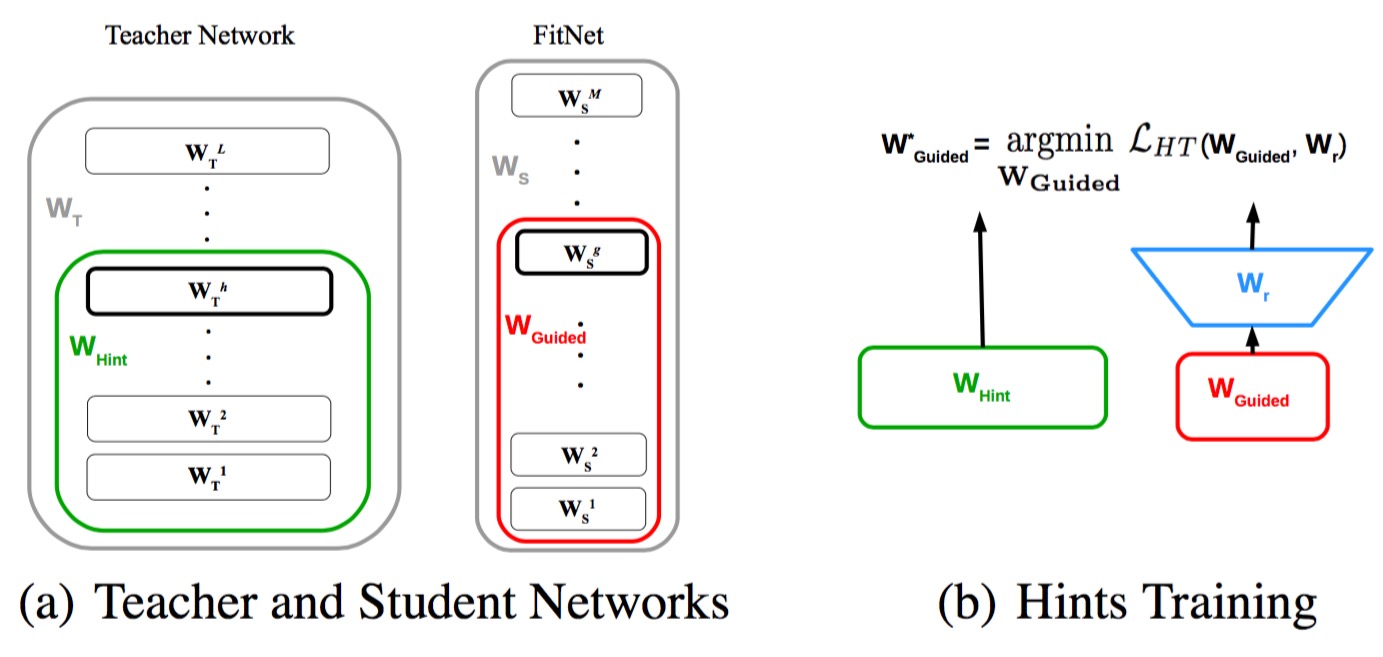
如上图,之所以有Wr是因为teacher network的层输出与小网络的往往是不一样的,因此需要这样一个mapping来匹配,并且这个mapping也是需要学习的。paper中提到说用多加一个conv层的方法比较节省参数(其实也比较符合逻辑),然后这个conv层不加padding,不stride。下面是一个公式表述:

实际的训练过程如下图所示。

图中过程写的比较复杂,实际上只是做了两步:
- 通过HT来训练前半层
- 通过KD来训练整个网络
最后的效果居然比teacher网络还要好,非常吃惊
